Introducing the Rational Speech Act framework
Day 1: Language understanding as Bayesian inference
The Rational Speech Act (RSA) framework views communication as recursive reasoning between a speaker and a listener. The listener interprets the speaker’s utterance by reasoning about a cooperative speaker trying to inform a naive listener about some state of affairs. Using Bayesian inference, the listener infers what the state of the world is likely to be given that a speaker produced some utterance, knowing that the speaker is reasoning about how a listener is most likely to interpret that utterance. Thus, we have (at least) three levels of inference. At the top, the sophisticated, pragmatic listener, , reasons about the pragmatic speaker, , and infers the state of the world given that the speaker chose to produce the utterance . The speaker chooses by maximizing the probability that a naive, literal listener, , would correctly infer the state of the world given the literal meaning of .
At the base of this reasoning, the naive, literal listener interprets an utterance according to its meaning. That is, computes the probability of given according to the semantics of and the prior probability of . A standard view of the semantic content of an utterance suffices: a mapping from states of the world to truth values.
// possible states of the world
var worldPrior = function() {
return uniformDraw([
{shape: "square", color: "blue"},
{shape: "circle", color: "blue"},
{shape: "square", color: "green"}
])
}
// possible one-word utterances
var utterances = ["blue","green","square","circle"]
// meaning funtion to interpret the utterances
var meaning = function(utterance, world){
return utterance == "blue" ? world.color == "blue" :
utterance == "green" ? world.color == "green" :
utterance == "circle" ? world.shape == "circle" :
utterance == "square" ? world.shape == "square" :
true
}
// literal listener
var literalListener = function(utterance){
Infer({method:"enumerate"}, function(){
var world = worldPrior();
var uttTruthVal = meaning(utterance, world);
condition(uttTruthVal == true)
return world
})
}
viz.table(literalListener("blue"))
Exercises:
- Check what happens with the other utterances.
- In the model above,
worldPrior()returns a sample from auniformDrawover the possible world states. What happens when the listener’s beliefs are not uniform over world states? (Hint, use acategoricaldistribution by callingcategorical({ps: [list_of_probabilities], vs: [list_of_states]})).
Fantastic! We now have a way of integrating a listener’s prior beliefs about the world with the truth functional meaning of an utterance.
What about speakers? Speech acts are actions; thus, the speaker is modeled as a rational (Bayesian) actor. He chooses an action (e.g., an utterance) according to its utility. The speaker simulates taking an action, evaluates its utility, and chooses actions in proportion to their utility. This is called a softmax optimal agent; a fully optimal agent would choose the action with the highest utility all of the time. (This kind of model is called action as inverse planning; for more on this, see agentmodels.org.)
In the code box below you’ll see a generic softmax agent model. Note that in this model, agent uses factor (not condition). factor is a continuous (or, softer) version of condition that takes real numbers as arguments (instead of binary truth values). Higher numbers (here, utilities) upweight the probabilities of the actions associated with them.
// define possible actions
var actions = ['a1', 'a2', 'a3'];
// define some utilities for the actions
var utility = function(action){
var table = {
a1: -1,
a2: 6,
a3: 8
};
return table[action];
};
// define speaker optimality
var alpha = 1
// define a rational agent who chooses actions
// according to their expected utility
var agent = Infer({ method: 'enumerate' }, function(){
var action = uniformDraw(actions);
factor(alpha * utility(action));
return action;
});
print("the probability that an agent will take various actions:")
viz.auto(agent);
Exercises:
- Explore what happens when you change the agent’s optimality.
- Explore what happens when you change the utilities.
In language understanding, the utility of an utterance is how well it communicates the state of the world to a listener. So, the speaker chooses utterances to communicate the state to the hypothesized literal listener . Another way to think about this: wants to minimize the effort would need to arrive at from , all while being efficient at communicating. thus seeks to minimize the surprisal of given for the literal listener , while bearing in mind the utterance cost, . (This trade-off between efficacy and efficiency is not trivial: speakers could always use minimal ambiguity, but unambiguous utterances tend toward the unwieldy, and, very often, unnecessary. We will see this tension play out later in the course.)
Speakers act in accordance with the speaker’s utility function : utterances are more useful at communicating about some state as surprisal and utterance cost decrease.
(In WebPPL, can be accessed via literalListener(u).score(s).)
With this utility function in mind, computes the probability of an utterance given some state in proportion to the speaker’s utility function . The term controls the speaker’s optimality, that is, the speaker’s rationality in choosing utterances.
// pragmatic speaker
var speaker = function(world){
Infer({method:"enumerate"}, function(){
var utterance = utterancePrior();
factor(alpha * literalListener(utterance).score(world))
return utterance
})
}
Exercise: Check the speaker’s behavior for a blue square.
We now have a model of the generative process of an utterance. With this in hand, we can imagine a listener who thinks about this kind of speaker.
The pragmatic listener computes the probability of a state given some utterance . By reasoning about the speaker , this probability is proportional to the probability that would choose to utter to communicate about the state , together with the prior probability of itself. In other words, to interpret an utterance, the pragmatic listener considers the process that generated the utterance in the first place. (Note that the listener model uses observe, which functions like factor with set to .)
// pragmatic listener
var pragmaticListener = function(utterance){
Infer({method:"enumerate"}, function(){
var world = worldPrior();
observe(speaker(world), utterance)
return world
})
}
Within the RSA framework, communication is thus modeled as in Fig. 1, where reasons about ’s reasoning about a hypothetical .
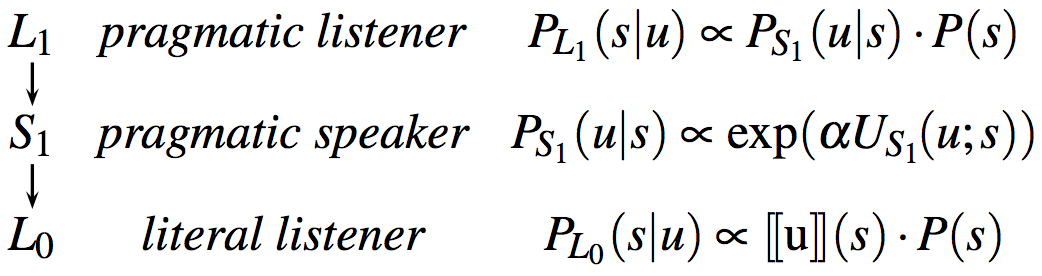
Application 1: Simple referential communication
In its initial formulation, reft:frankgoodman2012 use the basic RSA framework to model referent choice in efficient communication. To see the mechanism at work, imagine a referential communication game with three objects, as in Fig. 2.

Suppose a speaker wants to signal an object, but only has a single word with which to do so. Applying the RSA model schematized in Fig. 1 to the communication scenario in Fig. 2, the speaker chooses a word to best signal an object to a literal listener , who interprets in proportion to the prior probability of naming objects in the scenario (i.e., to an object’s salience, ). The pragmatic listener reasons about the speaker’s reasoning, and interprets accordingly. By formalizing the contributions of salience and efficiency, the RSA framework provides an information-theoretic definition of informativeness in pragmatic inference.
// Here is the code from the Frank and Goodman RSA model
// possible states of the world
var worldPrior = function() {
return uniformDraw([
{shape: "square", color: "blue"},
{shape: "circle", color: "blue"},
{shape: "square", color: "green"}
])
}
// possible one-word utterances
var utterances = ["blue","green","square","circle"]
// meaning funtion to interpret the utterances
var meaning = function(utterance, world){
return utterance == "blue" ? world.color == "blue" :
utterance == "green" ? world.color == "green" :
utterance == "circle" ? world.shape == "circle" :
utterance == "square" ? world.shape == "square" :
true
}
// literal listener
var literalListener = function(utterance){
Infer({method:"enumerate"},
function(){
var world = worldPrior()
condition(meaning(utterance, world))
return world
})
}
// set speaker optimality
var alpha = 1
// pragmatic speaker
var speaker = function(world){
Infer({method:"enumerate"},
function(){
var utterance = uniformDraw(utterances)
factor(alpha * literalListener(utterance).score(world))
return utterance
})
}
// pragmatic listener
var pragmaticListener = function(utterance){
Infer({method:"enumerate"},
function(){
var world = worldPrior()
observe(speaker(world),utterance)
return world
})
}
print("literal listener's interpretation of 'blue':")
viz.table(literalListener( "blue"))
print("speaker's utterance distribution for a blue circle:")
viz.table(speaker({shape:"circle", color: "blue"}))
print("pragmatic listener's interpretation of 'blue':")
viz.table(pragmaticListener("blue"))
Exercises:
- Explore what happens if you make the speaker more optimal.
- Add another object to the scenario.
- Add a new multi-word utterance.
- Check the behavior of the other possible utterances.
In the next chapter, we’ll see how RSA models have been developed to model more complex aspects of pragmatic reasoning and language understanding.
Table of Contents